How to save elephants by improving your code
The story of me refactoring an API endpoint and make it more performant.
One of the products we have at Codegram is Empresaula, our practice firm platform for the education sector that enables students to run a business in a controlled environment. Students buy and sell products within the platform, and in order to do so we implemented an internal messaging system. Businesses have internal email addresses that only work inside the platform, and we created a backend-powered fuzzy search to find the correct address when sending a new message.
The endpoint is quite critical: if the performance is low, email addresses will be hard to find, and this might affect the communications between businesses. We checked the New Relic dashboard for this endpoint and this is what it reported:
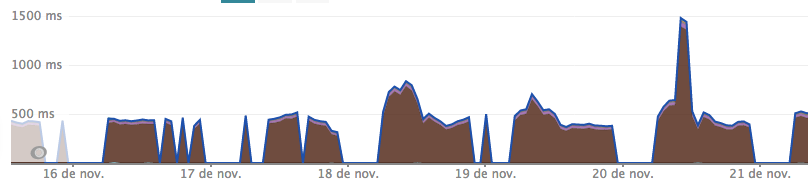
That's clearly a snake that has eaten some elephants
There are a few things we can analyze from this screenshot. First of all, during night time there's no activity. This is expected: since Empresaula is student-focused, and its activity is only in Spain, during night hours activity drops to zero. Another thing we can check is that the requests to that endpoint take no less than 400ms per request. Finally, we can see there's a spike that multiplies the request time by 3. In this post I'll focus on how we improved the request time.
How the endpoint works
When writing a message within Empresaula, a student starts writing the name of the business they want to contact. When there's a pause, what the user has written is sent to the endpoint, which performs the fuzzy search and returns the matching results. The student selects a result and starts again, so that they can send the same message to multiple businesses. This means we're sending a request to the server every time we want to find an email. That's why performance is so important here.
The original code
Built on Rails, the endpoint uses a class to find the emails that match the query:
class Business < ActiveRecord::Base
# attribute :id, :integer
# attribute :slug, :string
# attribute :single_department, :bool
end
module API
# This class lists all available business emails matching a given search key.
#
# In order to filter the emails, it first generates all possible emails and then
# filters those matching the given search key.
class BusinessEmailFinder
# Gets the emails matching the given `search_key`.
#
# search_key - a String with the search the user is trying to do
#
# Returns an Array.
def results_for(search_key)
business_emails.select do |email|
email.match(Regexp.escape(search_key.downcase))
end
end
private
attr_reader :business
# Internal: Builds all the emails available for the given business.
#
# Returns an Array.
def business_emails
businesses.flat_map do |business|
if business.single_department?
[build_email(:info, business.slug)]
else
departments.sort.map { |department| build_email(department, business.slug) }
end
end
end
# Internal: Builds the email for the given department and business slug.
#
# Returns a String.
def build_email(department, slug)
"#{department}@#{slug}.com"
end
# Internal: Finds the departments the given user can interact with.
#
# Returns an Array.
def departments
%w[reception human_resources accounting purchasing sales]
end
# Internal: Finds the business that can interact with the given one.
#
# Returns an Array.
def businesses
@businesses ||= Business.all
end
end
endLet's check what this class does. It finds all the businesses in the system, and for each business it builds a set of emails. If the business is configured as a single department, it builds a single email, otherwise it builds an email for each department. Finally, it selects all emails that match the given query, passed as a regular expression.
Improving the endpoint performance
The previous class is not actually making any use of the Business object: the data it uses comes straight from the database and it's not using any of the (many) methods defined in the model class. This is good, since it means we can actually improve the performance... by dropping the whole Business object:
def businesses
@businesses ||= Business.pluck(:slug, :single_email)
endWith this change we're using the pluck method from ActiveRecord. pluck will give us an array with all the values in the given fields: pluck(:id) will gives an array of all the IDs in the database for that particular resource, while pluck(:id, :name) will give as an array of arrays, where the nested arrays contain the values in these fields, ordered, so result[0][1] will return us the name of the first resource the database returns.
The actual benefit of using pluck is that we're only asking the data we need and we're also skipping building the Business object that wraps it. If we used the select method we'd still be building the Ruby object (although with only the data we asked for).
We need to adapt the rest of the class to use this new data structure:
def business_emails
businesses.flat_map do |slug, single_email|
if single_department?
[build_email(:info, slug)]
else
departments.sort.map { |department| build_email(department, slug) }
end
end
endWe deployed these changes, and here's what New Relic outputs in the endpoint performance graph:
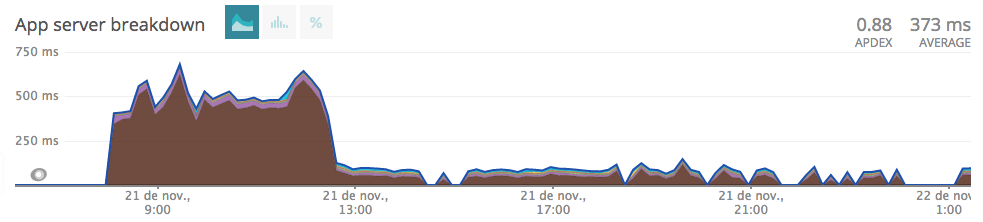
Can you see where the deployment took place? 😄
Reviewing the graph, we see that performance has dropped to around 100ms per request. Much better performance than the initial 400ms/req!
Note: The title of this post is a reference to The Little Prince, a book by Antoine de Saint-Exupéry. If you haven't read it, now's the time!
Photo by Tobias Adam on Unsplash


